Proof summary for aperiodicity of Rule 30
This is rule 30.
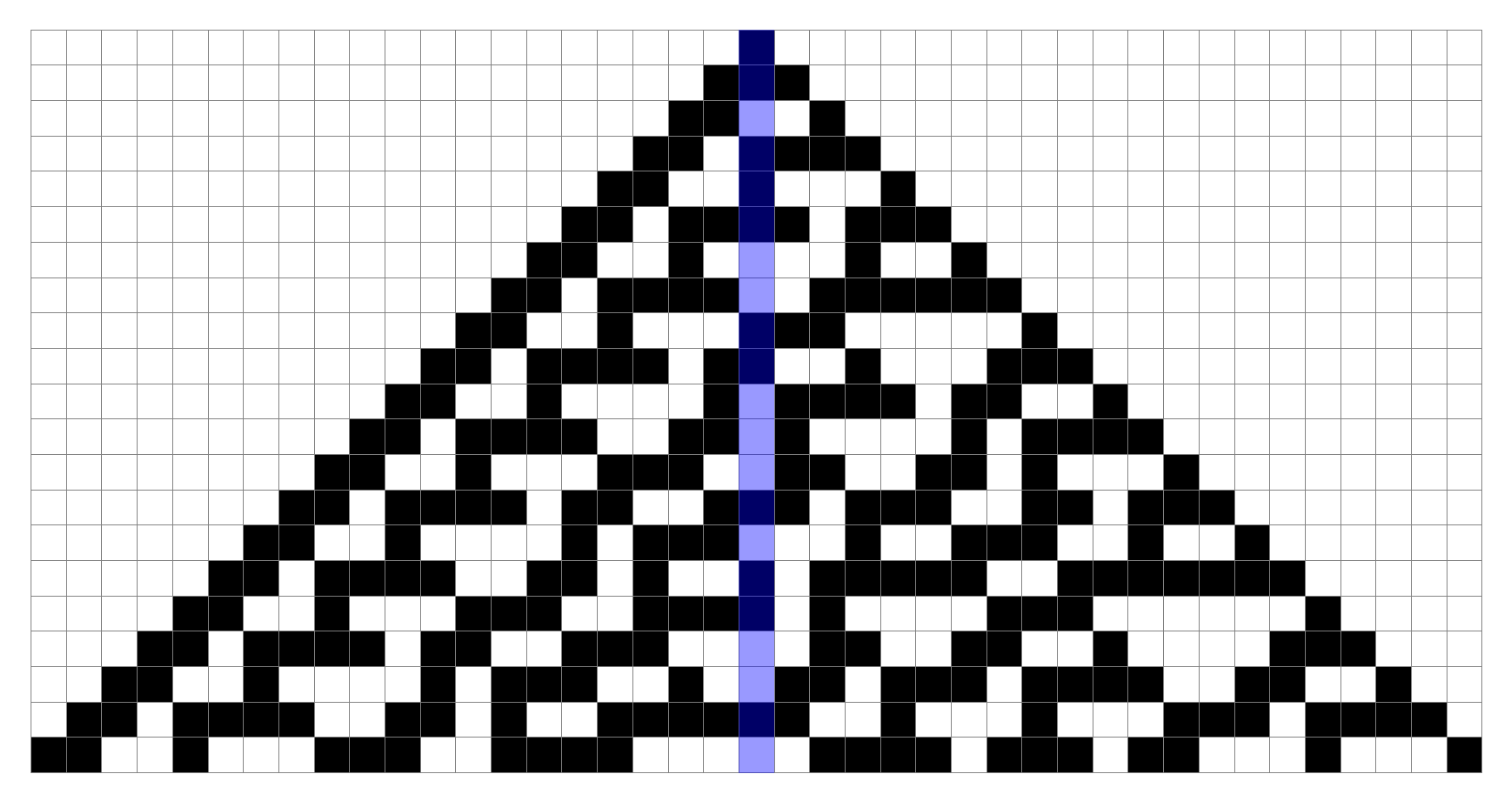
The center column is highlighted, as we are interested in determining whether or not it’s possible for it to ever degenerate into a cyclic pattern.
Today, I have a pretty good outline for how to show that it cannot.
Rule 30 as boolean algebra
We can always substitute variables in place of the hard 1s and 0s you usually deal with in cellular automata.
1 variable
Here’s one of the simplest replacements we could do.

Here, we merely replaced the single cell that starts all this, the \(1\) at the top, with $a$. That $a$ is propagated through the system exactly how the $1$ would be. Note that it would also be legitimate (if boring) to let $a=0$, in which case we’re left with an empty universe.
2 variables
If we add another variable, things begin to get interesting:
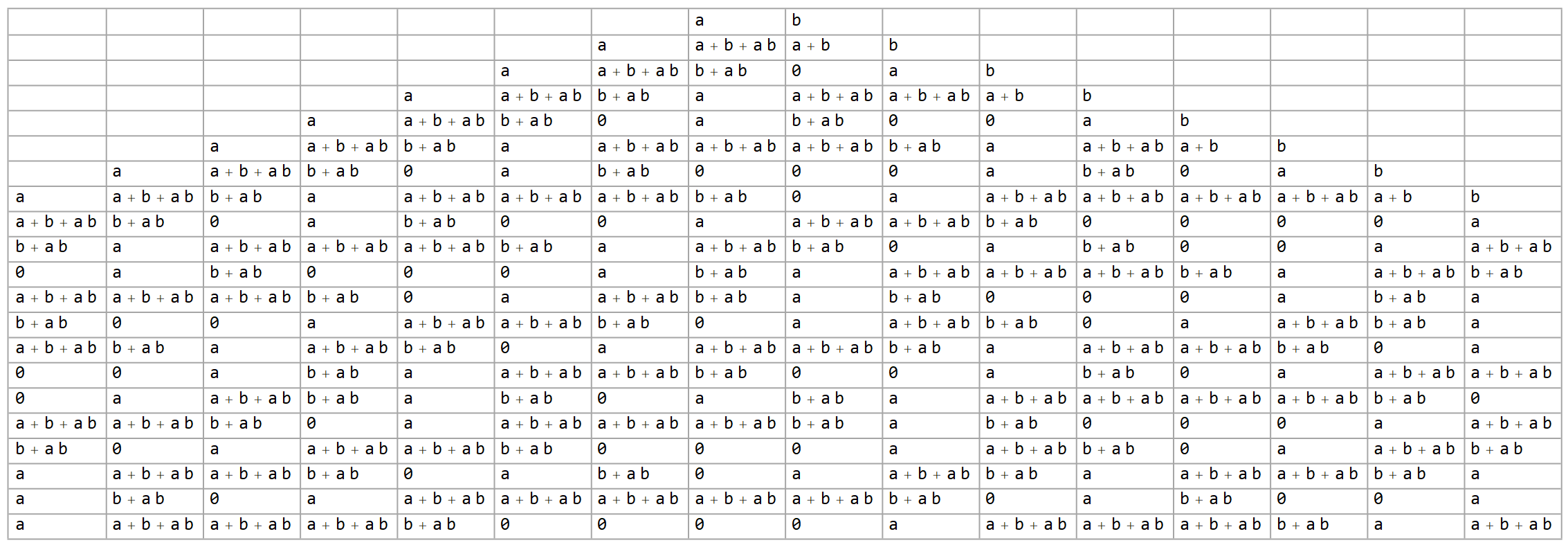
If we let $a=0,b=1$, then $b$ becomes the center column exactly as before. If we set $a=1$, however, it becomes the de facto center column*, regardless of the value of $b$. For a while, I thought there may be a trick along those lines to show that neither one could therefore be cyclic, but I wasn’t able to find anything, other than a conclusion that the appearances of $a$ and $b$ must be aperiodic even if the resulting pattern is not.
| $0$ | $b+ab$ |
| $a$ | $a+b+ab$ |
for 2 variables.
Apart from that, the situation is also getting slightly messier. We now have several values we see coming up repeatedly, listed in the table to the right. This is our first look at something that will become critical later, that new expressions are generally built by pasting two different sets together.
* We don’t mean literal center column here, but rather that it will contain the same pattern found in the typical Rule 30 configuration with a single $1$ cell in the center column seeding the structure.
K.I.S.S.
Incidentally, without simplification, an algebraic approach would be immediately intractable. If all we do is apply $f(a,b,c):=a+b+c+bc$, we can see the problem after only a couple of steps, in the same 2-variable configuration used above:
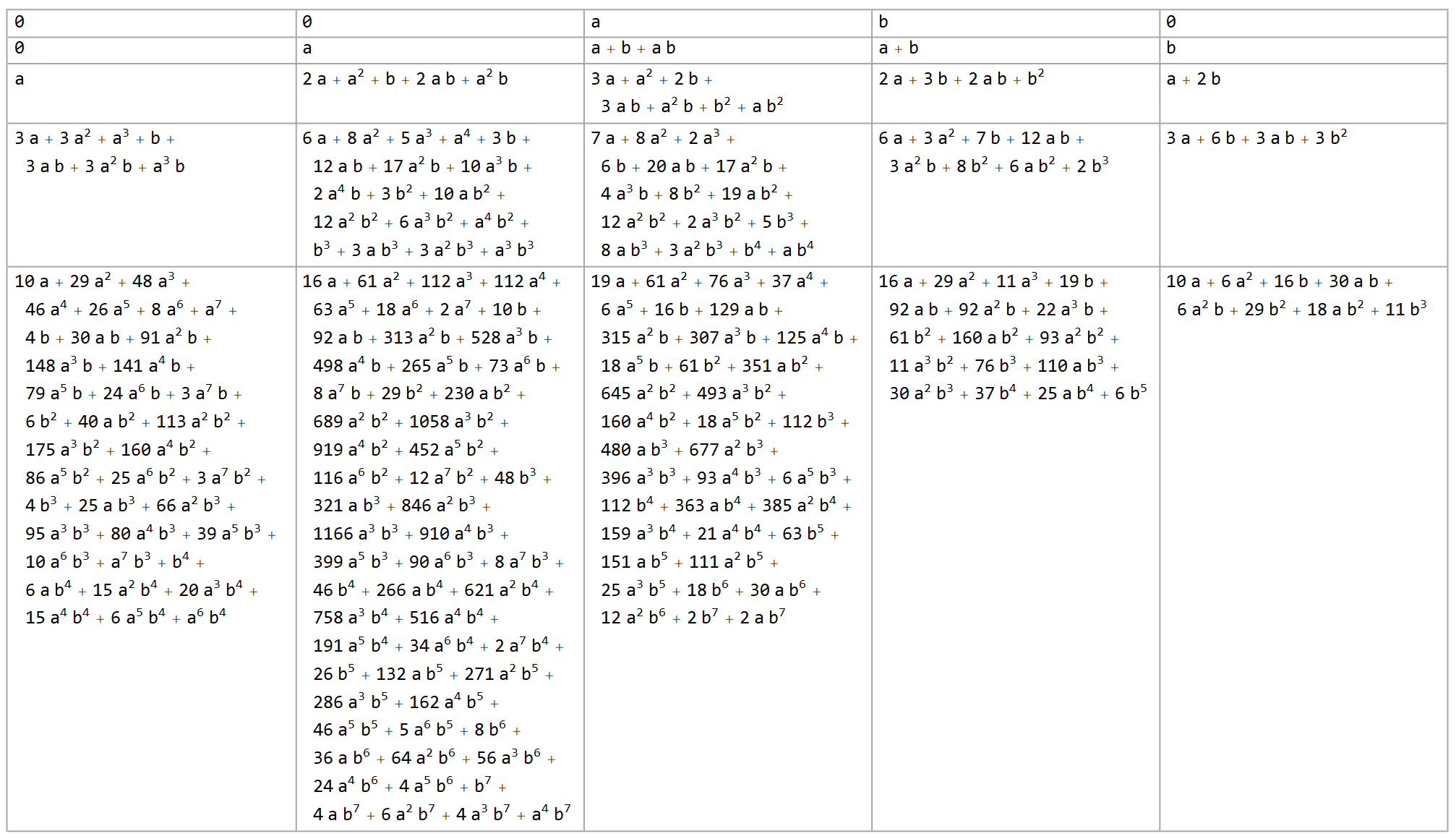
To limit the combinatorial explosion, there are two simple optimizations we can make since we’re dealing with boolean values. First, all exponents can be dropped, since $0^m=0$ and $1^m=1$ for any $m$. Second, we drop any terms with even coefficients, and strip the odd coefficients, which takes our expressions most of the way toward$\pmod{2}$ as they’re meant to be. Alas, even after all that, we’ll still face doubly exponential growth.
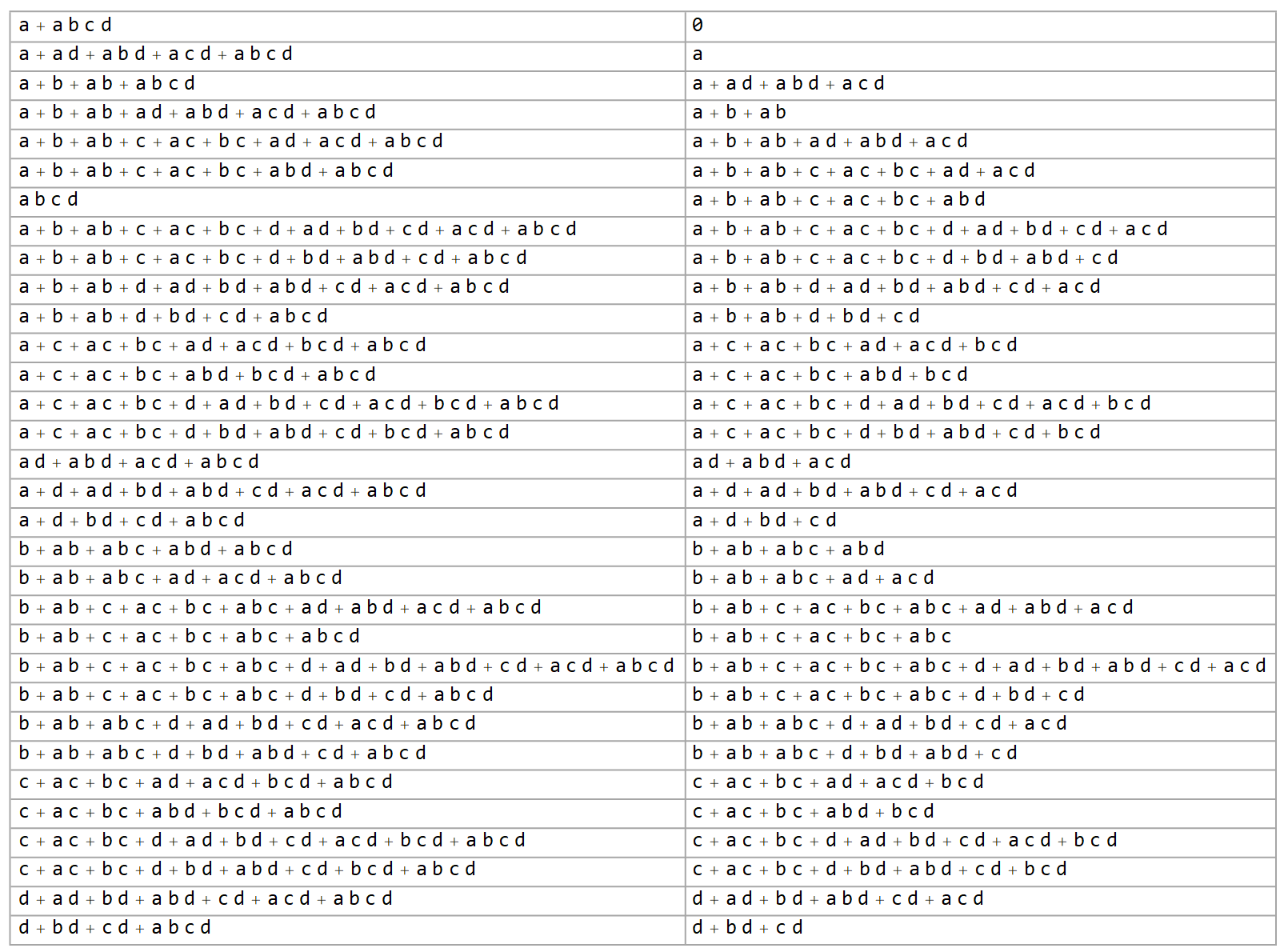
3 variables
When we add a third variable, things move into full gear.
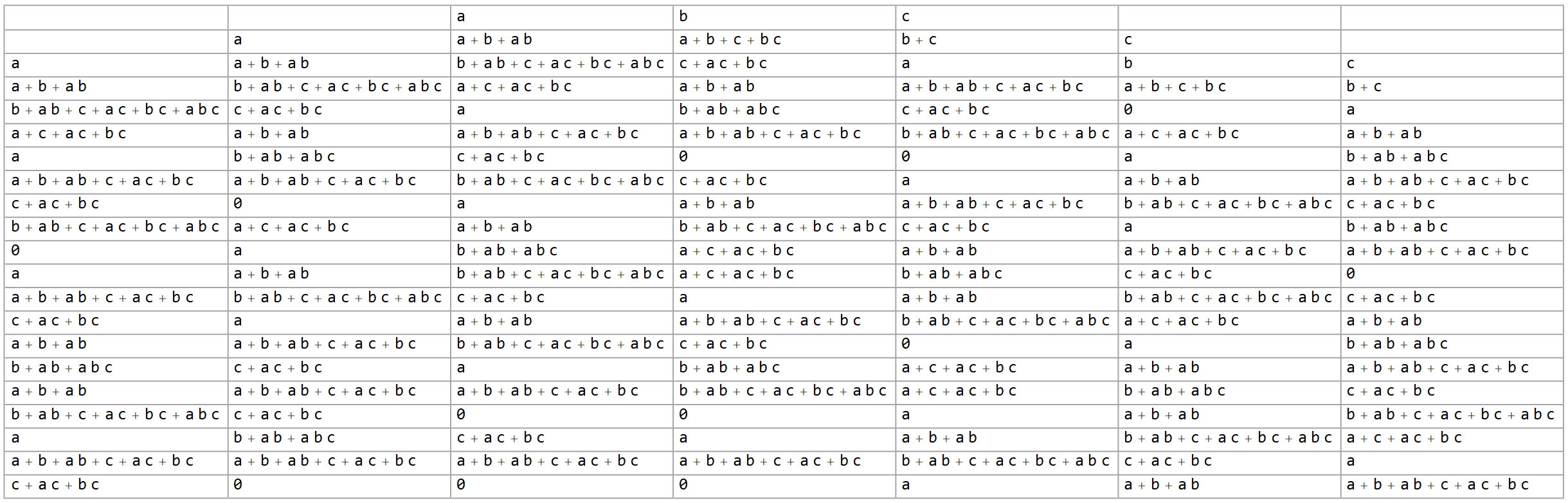
we’re effectively shifting forward time by one step, since
111 is the second row following a single start cell.| $0$ | $c+ac+bc$ |
| $a$ | $a+c+ac+bc$ |
| $a+b+ab$ | $a+b+ab+c+ac+bc$ |
| $b+ab+abc$ | $b+ab+abc+c+ac+bc$ |
Although there are clearly a lot of new expressions here, not all possible expressions are represented. For $k$ variables, able to combine in up to $2^k$ additive terms, each of which may itself include or not include $k$ variables, the number of raw possible expressions grows doubly exponentially as $2^{2^k}$. That growth rate has not been the case so far, but it will be from here on out, presumably a result of reaching the three operands that Rule 30 expects. As a result, the number of distinct algebraic expressions quickly becomes unmanageable even after our simplifications.
Fortunately, we won’t need to manage it. There’s an invariant property that readily scales with this, and that’s what we’ll be using here.
Continuing the pattern
| term | count |
|---|---|
| $a$ | 32 |
| $b$ | 32 |
| $c$ | 32 |
| $d$ | 32 |
| $ab$ | 32 |
| $ac$ | 32 |
| $ad$ | 32 |
| $bc$ | 32 |
| $bd$ | 32 |
| $cd$ | 32 |
| $abd$ | 32 |
| $acd$ | 32 |
| $abcd$ | 32 |
| $abc$ | 16 |
| $bcd$ | 16 |
| $0$ | 1 |
from 4-variable
distinct expressions.
| term | count |
|---|---|
| $a$ | 4 |
| $b$ | 4 |
| $c$ | 4 |
| $ab$ | 4 |
| $ac$ | 4 |
| $bc$ | 4 |
| $abc$ | 2 |
| $0$ | 1 |
from 3-variable
distinct expressions.
There are a few expressions that do appear that we’ll be ignoring, but this is because they’re either part of the cycling diagonals off to the side, which doesn’t help us, or because it’s one of the first few entries in the column, which don’t actually repeat. (Interestingly, any expression in the form $a+b+c+bc$ falls into this category, and only appears once.) Given that, let’s focus only on expressions that appear on row $n\geq 3$, in the center column.
| # variables ($k$) | distinct cell expressions |
|---|---|
| 1 | $2^1=2$ |
| 2 | $2^2=4$ |
| 3 | $2^3=8$ |
| 4 | $2^6=64$ |
| 5 | $2^{12}=4096$ |
| 6 | $2^{24}=16777216$ |
| 7 | $2^{48}=281474976710656$ |
For all $k \geq 3$, if you process sufficiently many rows to see every legal expression at least once, you’ll find that within those $2^{3\cdot 2^{k-3}}$ distinct expressions, if you chop up the polynomials and take a raw count of all monomial terms, every possible term appears, and each one appears in precisely one-half of all expressions. The only exception to this is the null-set-expression $0$, which may occur as infrequently as $1$ in $2^{2^k}$ cells (but needs further research), and any triplets like $bcd, cde, def, \ldots$, consisting of exactly three distinct consecutive in-range variables. There are only $k-2$ of these, and they appear in only a quarter of the overall list.
But back to the main story here. Yes, they all share very equitably, and in fact, it’s so even that if you remove every expression containing any given monomial or subexpression, the count of all remaining monomials is exactly halved, suggesting an extremely organized distribution.
Take the 4-variable case as an example, which will have $64$ distinct expressions. This means that $32$ of those will have $a$ as a monomial, and $16$ of the other $32$ will have $b$ as a monomial, and $8$ of the remaining $16$ will have $c$ as a monomial, and finally $4$ of those last $8$ will have $d$ as a monomial (with no $a$, $b$, or $c$). That leaves $4$ expressions to be accounted for; of those, $0$ uses one slot, and the other three will all have all multivariable monomials.
Any of those final four expressions is indicative of a vertical run of $0$s of width at least $4$ and height at least $2$. This principle can be extended to any number of variables to show arbitrarily large contiguous spans of $0$, disallowing any periodicity.
Ratcheting up complexity
The tables we’re building are additive in the sense that, upon adding a new variable to the seed row, no existing addends will ever be removed as a result. This property gives us a welcome measure of stability. Instead, those cells that do change values can do so only by taking on additional additive terms, all of which must be divisible by the new variable.
Given that, let’s look at the actual driving force behind the complexity generation: the multiplicative operation. In fairness, the real source of the complexity is the interweaving of multiplication and addition (as is true in literally all things), but combinatorially speaking, the multiplication is the killer.
The additions are able to mix and match terms to some extent, and thus are half of that double exponential, but the multiplications are able to glue together what effectively become new proxy variables which must be independently tracked downstream, amplifying the capacity of the additions to swirl together novel expressions. In particular, every new seed variable appears to permeate the system sufficiently such that all $2^k$ possible terms appear.
That said, it’s worth repeating that although all terms appear, not all possible expressions do. As mentioned, the general $a+b+c+b c$ form is a one-and-done, and also worth special attention is the lack of solitary single variable expressions: $a$ is the only one that you’ll see, discounting degenerate cycles on the diagonals. For any variable past $a$, you will never see it on its own after being introduced; in every expression where it appears as a term, it’s always part of a larger whole, e.g. you’ll see $c+ac+bc$, at the very least. This is a general pattern that seems to hold: $d$ never appears on its own but requires at least $d+bd+cd$, and so forth. Close examination of the genesis of these terms in the tables below makes some sense of this behavior.
Although these tables are obviously becoming unwieldy, here are the beginnings of the 4- and 5-variable progressions.
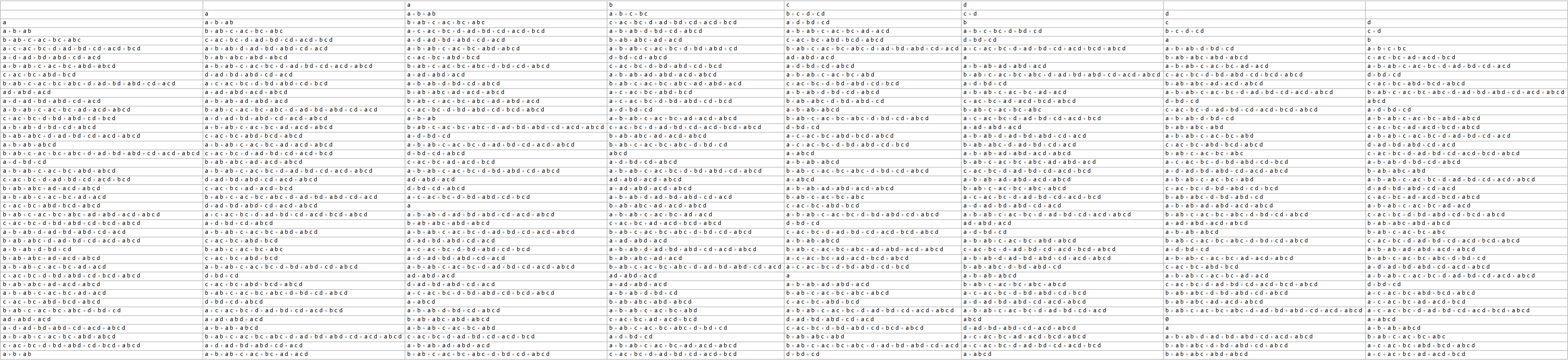
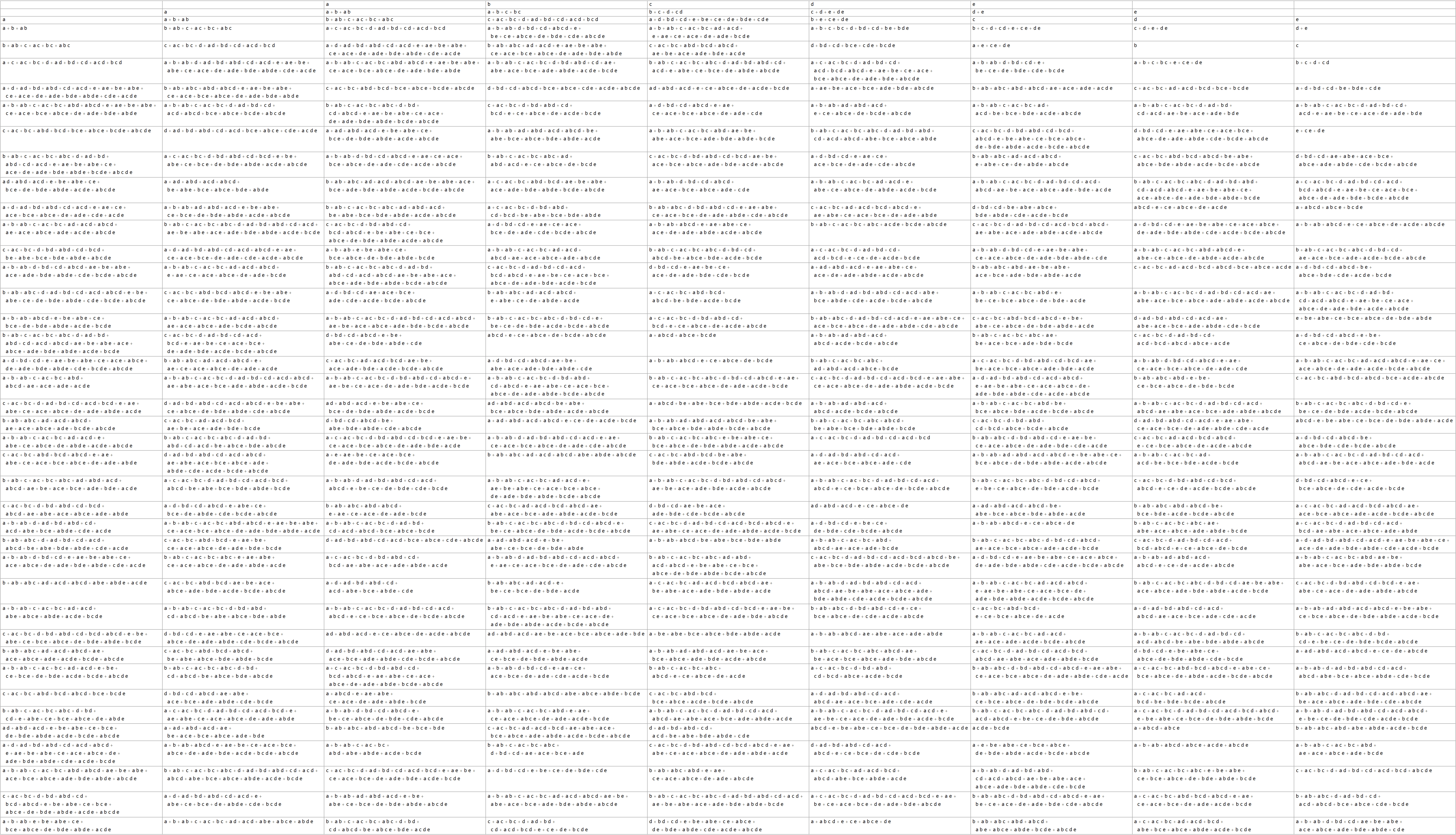
Without serious optimization, identifying the distinct expressions for the 5-variable case is right at the limit of what my computer can reasonably handle using 64gb of memory and a day of computing time. I suspect that no amount of optimization would allow brute force verification of the 6-variable case without special hardware. So while on the one hand, I am basing my theory on an extremely limited data set, the specific nature of the data strongly suggests to me that the patterns identified likely hold at any level, but to prove it, I still need to work out a more compelling theory of how those exact properties do hold.
Mechanism of operation
| $0$ | $c+ac+bc$ |
| $a$ | $a+c+ac+bc$ |
| $a+b+ab$ | $a+b+ab+c+ac+bc$ |
| $b+ab+abc$ | $b+ab+abc+c+ac+bc$ |
Consider the progression when starting with $\{a,b,c\}$. You get $8$ distinct expressions from that; in fact, we’ll pop up that table now.
Now consider the progression when starting with $\{b,c,d\}$. By this, I mean with $b$ and $c$ in their usual columns, and padded by $0$ as always, so yes: this is isomorphic to the $\{a,b,c\}$ progression. See, I’m attempting to lay conceptual groundwork for picturing them coming together from their own individual starting points, so we can think through what happens when we combine them as with $\{a,b,c,d\}$.
It should be obvious that $\{b,c,d\}$ on its own will also generate eight unique expressions, and essentially the same ones that are given here. To determine them exactly, it generally suffices to simply shift all the variables forward or backward. Doing this, we find that all of the expressions for $\{b,c,d\}$ will be different (excepting $0$).
Conceivably, the merging process between these two sets will somehow come to settle on $8^2=64$ distinct expressions, highly suggestive of pairing, but it’s unclear how to get more precise than that. And thus I guess we’ve gotten to where I’m stuck.
I’m probably better off sticking with the inductive-like approach of considering what happens when you add one more seed variable. The even splitting of terms completely regularly between all expressions, as well as the number of expressions itself simply repeatedly squaring, both scream that there is a very orderly process behind this part of things, but I can’t put my finger on it if so. And I wish I could, because a proof immediate follows if I could show this distribution holds, or even a decent tangential result.